
Una vez terminada la elección, creo que es buen momento para tratar de desmontar algunos mitos que aparecen cada cuatro años alrededor de este proceso: desde la supuesta criticalidad de los debates, hasta las historias de terror sobre encuestas manipuladas. El objetivo fundamental consiste en contribuir a eliminar estos relatos como focos de desinformación que pueden afectar la confianza del electorado en los procesos democráticos.
La encuesta fantasma: “a mí nunca me llamaron”
Más de una vez escuché en esta campaña (y en las anteriores), frases como “yo no creo en eso, a mí nunca me han llamado para encuestarme”. Esto solo evidencia lo mal que está nuestro sistema educativo, principalmente en el campo de las matemáticas y estadísticas.
Estas narrativas que desacreditan herramientas estadísticas legítimas terminan erosionando la confianza en el proceso electoral y abriendo espacio a la desinformación.
Primero, una muestra estadística es, por definición, una herramienta usada para estimar algún valor de una población general sin tener que hacer dicha medición en todos los elementos o individuos que forman el conjunto completo. Eso sí, la muestra debe cumplir con ciertos criterios de tamaño y aleatoriedad, como que todos los miembros del conjunto deben tener la misma probabilidad de ser elegidos.
¿Cuál es esa probabilidad? Tomemos como ejemplo la última encuesta del CIEP del 28 de enero pasado, que usó una muestra de 1501 personas. Eso implica que, en un padrón electoral de 3,7 millones de personas, solo 4 de cada 10,000 personas iba a ser encuestada. Por eso, el hecho de que uno mismo o nadie de su círculo cercano haya sido encuestado no invalida la encuesta ni la hace menos confiable; simplemente refleja la matemática detrás de las muestras aleatorias y el tamaño de la población.
La persistente leyenda de la encuesta manipulada
Ya muchos analistas y científicos han dicho lo mismo: las encuestas no están hechas para “pegar”. Pero decirlo de esa forma, posiblemente por exceso de cautela, también les quita un valor como herramienta predictiva que sí tienen en alguna medida.
Sin embargo, claro está, tampoco son bolas de cristal.
Muchas personas no comprenden qué quieren decir frases como “la encuesta tiene un margen de error del 3%, con un nivel de confianza del 95%”, y los medios rara vez se dedican a explicarlo (o quizá tampoco saben cómo).
En pocas palabras, eso significa que:
- Los valores de la población general pueden estar 3% arriba o debajo de lo observado en la muestra.
- Aún existe un 5% de probabilidad (100% - 95% = 5%) de que el valor que se trata de medir en la población (por ejemplo, el apoyo al candidato X) esté fuera de ese margen de error. Eso es una probabilidad baja, pero NO IMPOSIBLE, lo cual es muy importante de considerar al leer los datos de la encuesta.
La realidad es que todas las encuestas acertaron en ver la tendencia al alza constante de Laura Fernández a lo largo de la campaña electoral, como lo demuestra la línea azul en el siguiente gráfico:
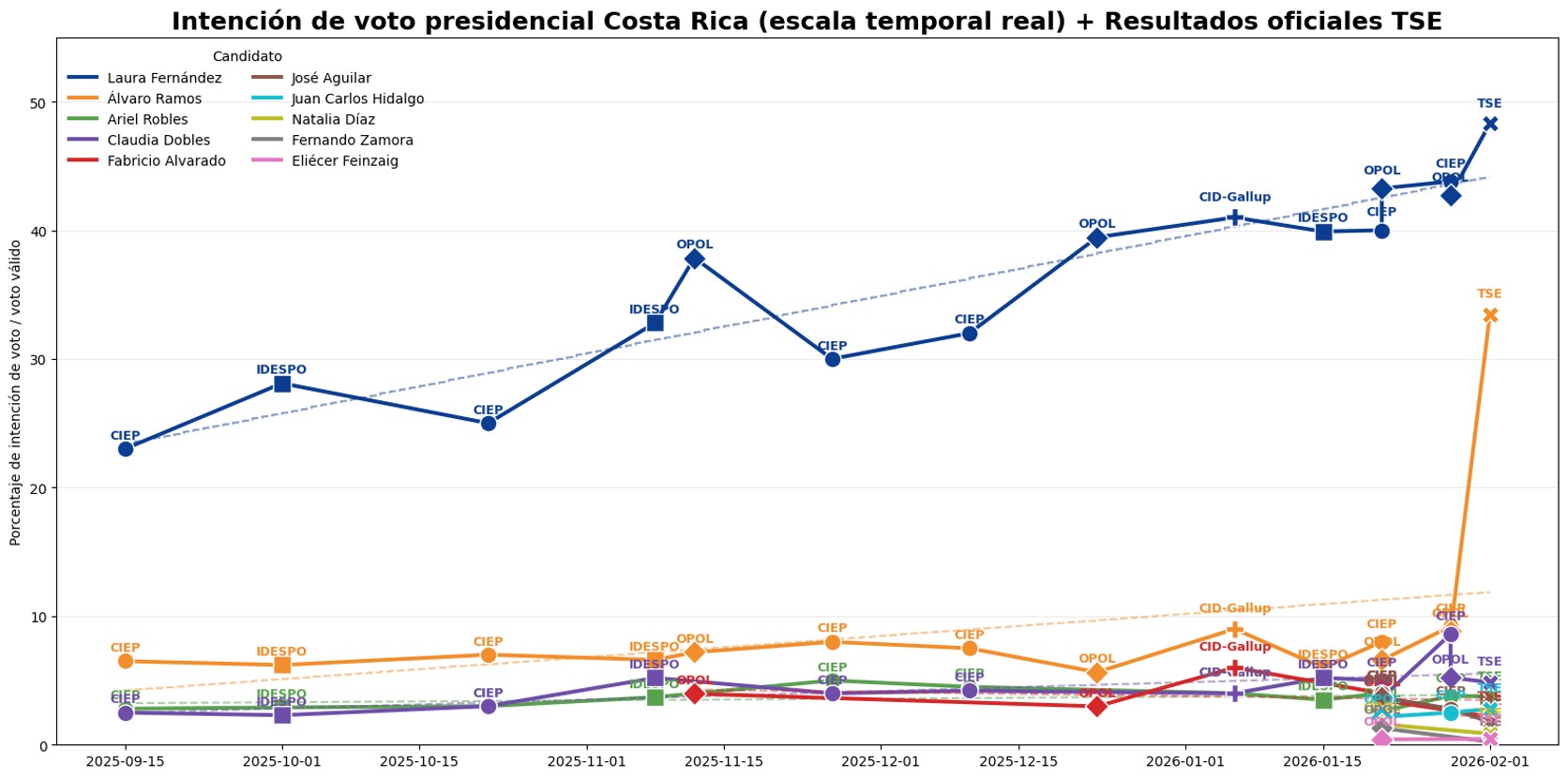
Lo que sin duda nadie anticipó (o al menos no podía inferirse a partir de una lectura simple de las encuestas) fue el crecimiento meteórico de Álvaro Ramos el propio día de las elecciones.
No obstante, usando experiencias pasadas y la misma encuesta del CIEP del 21 de enero es posible encontrar una explicación:
- En elecciones pasadas ya se ha dado en Costa Rica el fenómeno del voto útil, con mucha gente cambiando de candidato el propio día de la elección al ver que su favorito no tiene opción, en busca de forzar una segunda ronda.
- Las encuestas siempre pusieron a Álvaro Ramos en el segundo lugar.
- El 30% de las personas indecisas manifestaron que definirían su voto el día de la elección, mientras que el 70% lo haría durante la semana previa. Por lo tanto, gran parte de este comportamiento no fue identificado por las encuestas debido a la veda establecida a partir del 28 de enero.
- El voto de algunos partidos como Frente Amplio fue mayor para diputaciones que para presidente, mientras que PLN obtuvo un resultado inverso.
Consecuentemente, es evidente que muchas personas que previamente respaldaban opciones como CAC o FA optaron por apoyar al candidato presidencial percibido como principal favorito para quedar en segundo lugar, aunque mantuvieron su preferencia habitual en la elección de diputaciones. De igual forma, quienes permanecían indecisos hasta el último momento también tendieron a elegir al aspirante que consideraban con mayores posibilidades de éxito.
Por lo tanto, no es que las encuestas sean inútiles, lo que sucede es que representan solo una parte del panorama. Para aproximar mejor los resultados finales, es necesario utilizar modelos computacionales de simulación que empleen las encuestas como insumo, pero que también integren factores como el voto útil (o voto estratégico) en la generación de escenarios probables.
El mito del debate decisivo
Analicemos las siguientes afirmaciones a la luz de la siguiente hipótesis: “Los debates son fundamentales para que la ciudadanía se informe y decida su voto”.
Hechos:
- Laura Fernández solo fue a 3 debates, mientras que otros candidatos como Álvaro Ramos, Claudia Dobles, Eli Feinzaig, Juan Carlos Hidalgo y Natalia Díaz, por mencionar solo a algunos de los que lideraron partidos ya consolidados, fueron a más de 9.
- Es la opinión general que el desempeño de Laura Fernández fue quizás el peor, o al menos, ni de cerca el mejor en dichos espacios.
- La participación de Álvaro Ramos no fue especialmente destacada en ningún debate. Otras figuras como Claudia Dobles, Natalia Díaz, Ariel Robles, e incluso José Aguilar, tuvieron momentos más brillantes, algunos que incluso se hicieron virales.
- En los debates, Laura Fernández recibió ataques constantes de sus adversarios, a los cuales rara vez respondió de forma eficaz u oportuna.
Entonces, si los debates fuesen tan importantes como siempre hemos creído, probablemente habríamos observado lo siguiente:
- Laura Fernández perdiendo apoyo luego de sus participaciones.
- Crecimiento de las demás candidaturas, en mayor o menor medida.
- Un resultado de la elección más cercano al objetivo de los adversarios de Laura Fernández, de extender la elección a una segunda ronda.
Pero no fue eso lo que vimos. Antes y después de los debates, y luego el día de las elecciones, la tendencia alcista de Laura Fernández nunca cambió, mientras que figuras que tuvieron momentos memorables en los debates no lograron sus objetivos electorales.
Aunque es cierto que figuras poco conocidas pueden ganar visibilidad en estos espacios (como ocurrió con José Aguilar tras el debate del TSE), para que una candidatura llamativa se vuelva realmente viable se requieren auténticos motores de motivación en la población. Estos impulsos no suelen surgir de los debates, sino de contextos específicos como los que favorecieron el ascenso de Luis Guillermo Solís en 2014 (el temor a los extremos del Frente Amplio y el Movimiento Libertario), de Carlos Alvarado en 2018 (el rechazo al extremismo religioso) y de Rodrigo Chaves en 2022 (la oposición a Figueres).
No quiero decir con esto que los debates no sean necesarios. No obstante, la saturación de este tipo de encuentros no parece mover la aguja mayormente y puede tender a cansar al electorado. Creo valioso un replanteamiento, por parte de los medios, tanto de la cantidad como del formato de estos contenidos.
En síntesis, las encuestas y los debates constituyen herramientas de análisis limitadas; no pueden considerarse fuentes definitivas ni instrumentos engañosos. Es fundamental interpretarlas dentro de su contexto, emplear criterios prudentes y complementarlas con otros enfoques metodológicos. La falta de precisión suele deberse a una interpretación incorrecta, más que a deficiencias propias del método.